November 30, 2022
Convr AI’s Data Lake Demystified

Data is an essential component of our products at Convr. This article describes the structure and method by which we deliver data to the Convr platform and applications.
The following diagram depicts how large volumes of data are ingested, processed, transformed, stored, and made accessible to users.
Components of Convr’s data architecture:
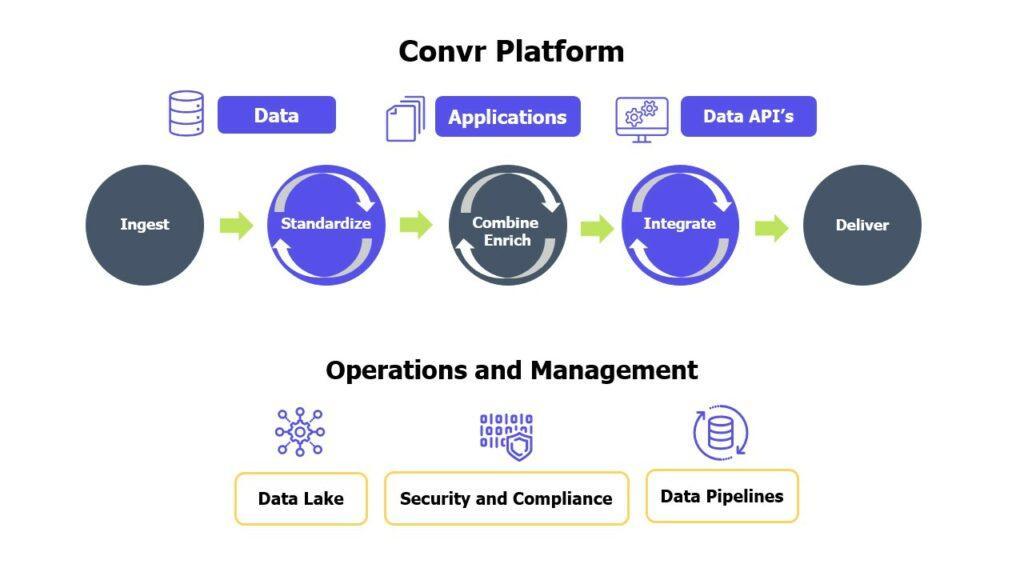
Ingest
Convr’s data pipelines ingest data from private, public, and social media sites. A few examples of data that is ingested:
- Firmographic, property, and geolocation data,
- Business inspection, violation, permit, and license data
- Business reviews from social media sites such as Yelp, Google
Retrieving data is time consuming and expensive. Our data pipelines automate the process of retrieving data from hundreds of different sources.
Standardize
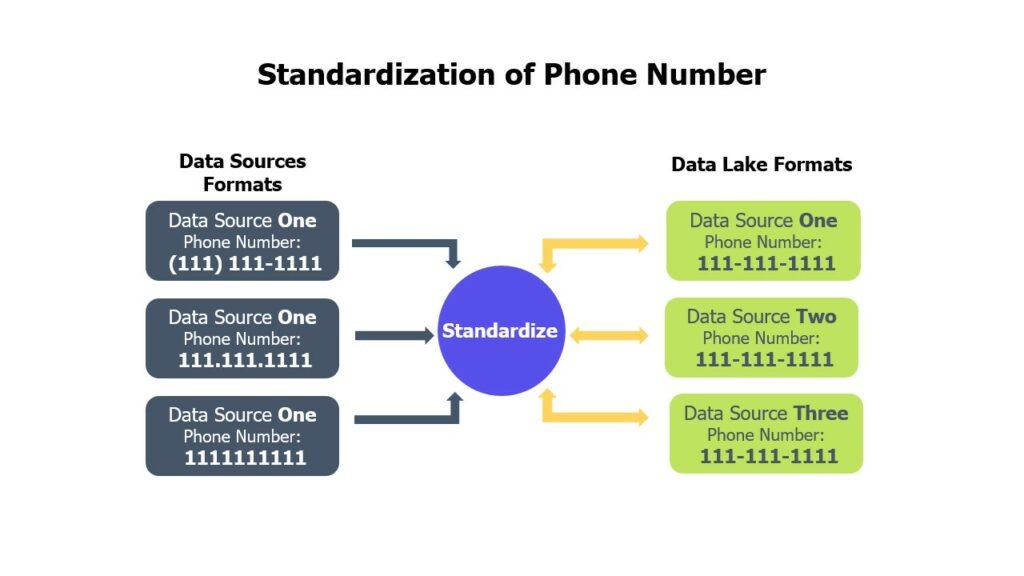
Since data sources collect information for different purposes, similar data is very often stored within different data models and on different database systems. Hence, the same information may be represented in a variety of ways and in different formats.
Data standardization converts information into a common format and common terminology. This delivers the ability to build reports and applications without having to create multiple mappings of the same data. For example, phone numbers are converted into one format:
Combine/Enrich
The data pipelines pull together the information for each company from all data sources. In addition, the data is enhanced with statistical risk scoring generated by data science models.
Integrate
In addition to ingesting data from various sources, the Convr application performs real-time integration of data from data analytics companies (such as Verisk, Core Logic, etc.) and social media sites (such as Google places, Yelp, and Bing)
Deliver
Data is delivered to our customers via Convr application UI (User Interface) and via data API’s.
Convr Data Infrastructure
Convr data pipelines run on AWS cloud resources. Data pipelines use S3 (Simple Storage Service) for storage and EC2 (Elastic Compute Cloud) nodes for processing.
Convr applications and data pipelines are implemented using open-source software:
- Python programming language
- ElasticSearch for our data lake
- Apache Spark™, Apache Kafka™ for data transformation
- Flask framework for web services and data API’s
- mySQL, Maria for our application databases
Our data stack philosophy:
- Look to mature open-source software with large community adoption and support rather than re-inventing the wheel
- Ensure the software scales easily as data is constantly increasing and new products are being added as the business grows
- Automate processes as much as possible by using CI/CD (Continuous Integration/Continuous Deployment) and other orchestration tools
Given the critical importance of data to our business and the business of our customers, Convr is committed to ensuring the standards and security of our data platform. We are also committed to the education of our customers and the transparency of our operations. Please look forward to other articles describing our infrastructure and capabilities.